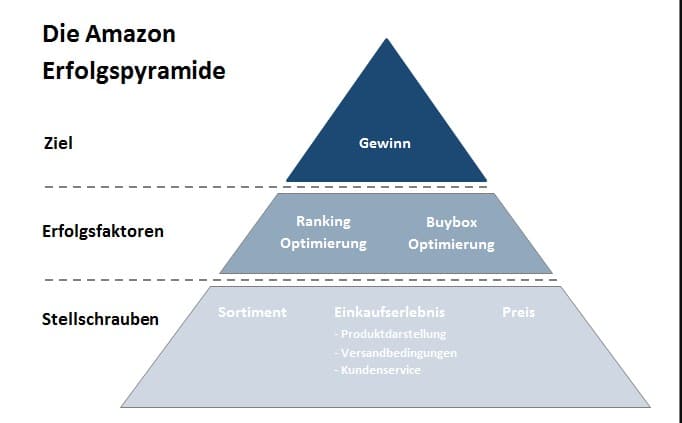
We wrześniu Google postawiło przede wszystkim na edukację SEOwców i webmasterów oraz zakończenie wdrażania zmian, które były na tapecie już od dłuższego czasu.
Poza tym obserwowaliśmy liczne wahania w wynikach wyszukiwania, ale żadna aktualizacja algorytmu nie została potwierdzona przez Google. Poniżej podsumowanie najważniejszych wrześniowych newsów.
2 września Google poinformowało za pośrednictwem Twittera o zakończeniu wdrażania aktualizacji Page Experience. O aktualizacji pisaliśmy już wielokrotnie na przestrzeni ostatniego roku. Została ona zapowiedziana już w maju 2020 roku, a jej wdrażanie rozpoczęło się w czerwcu 2021. Jeżeli chcesz dowiedzieć się więcej o aktualizacji Page Experience i ściśle powiązanym z nią pojęciem Core Web Vitals zapraszamy do wysłuchania 51 odcinka Dziennika Budowy Firmy, w którym szerzej opisujemy wprowadzane zmiany
17 września Google zaktualizowało informację o tym w jaki sposób generowane są znaczniki <title> w wynikach wyszukiwania. Przypominamy, że w sierpniu zostały wprowadzone zmiany w zakresie generowanie tytułów stron, o których więcej piszemy w sierpniowym podsumowaniu zmian w wyszukiwarce. Z kolei we wrześniu Google, na podstawie zgromadzonych opinii, wprowadził pewne zmiany w systemie generowania tytułów. Sprowadzają się one do tego, że elementy <title> będą używane w około 87% przypadków, nie jak wcześniej – w około 80% przypadków. W pozostałych przypadkach Google będzie wykorzystywało treść strony do wygenerowania tytułu. Zawartość tagu <title> będzie najczęściej podmieniana w sytuacjach, gdy nie użyto tagu title ale też dla podstron, w przypadku których ręcznie zdefiniowany tytuł jest zbyt lakoniczny, przestarzały, nieprecyzyjny lub wielokrotnie używany dla różnych stron.
Wrzesień nie obył się również bez drobnego problemu po stronie Google Search Console. 18 września Google poinformowało o opóźnieniu w wyświetlaniu danych w obrębie raportu skuteczności. Błąd został ostatecznie wyeliminowany 23 września.
ŹRÓDŁO 1: HTTPS://WWW.SEMRUSH.COM/SENSOR/ŹRÓDŁO 2: HTTPS://APP.SENUTO.COM/VISIBILITY-ANALYSIS/SERP-WEATHERŹRÓDŁO 3: HTTPS://ALGOROO.COM/
Z ciekawostek - w trakcie tegorocznego wydarzenia Search On, Google poświęcił szczególną uwagę nowym zastosowaniom technologii MUM (Multitask Unified Model). Nowa technologia Google ma zmienić sposób poszukiwania informacji, jak i sposób ich dostarczania. Algorytm będzie miał za zadanie udzielić maksymalnie trafnej odpowiedzi jeszcze szybciej i w najbardziej przystępny sposób. Wykorzystanie technologii szerzej opisuje wpis na blogu Google Polska, który znajdziesz pod linkiem do źródła.
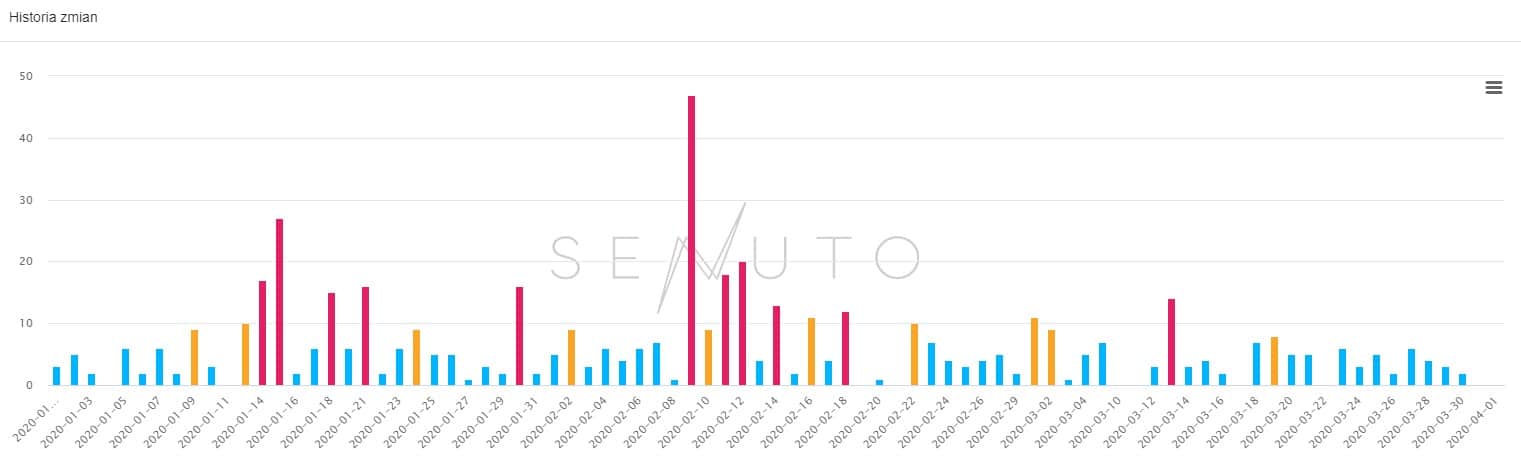
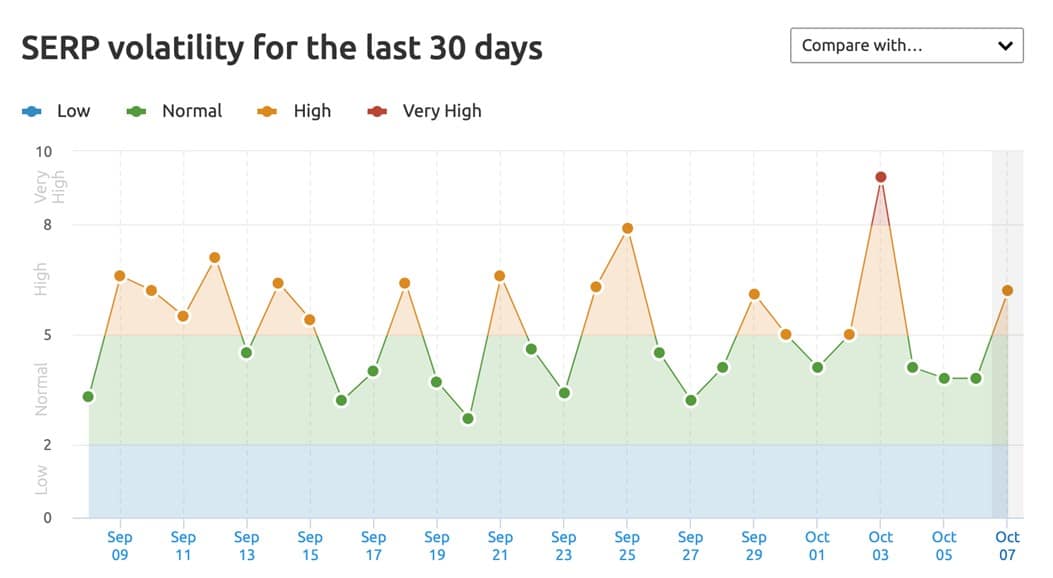
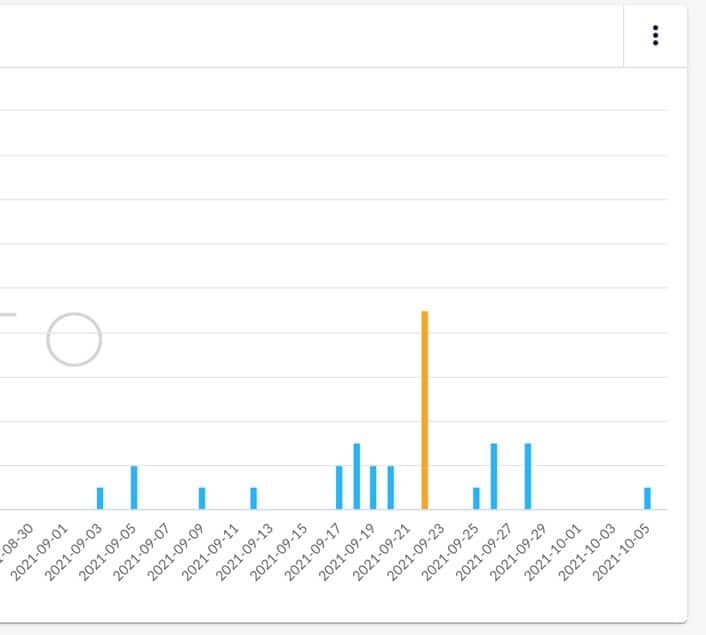
Praktycznie cały miesiąc był dość intensywnym okresem, jeżeli chodzi o fluktuacje w wynikach wyszukiwania. Mogliśmy zaobserwować całkiem sporo wahań wychodzących poza normę. Największe wahania, w polskich wynikach wyszukiwania, narzędzia odnotowały w okolicach 23 września. Intensywne fluktuacje obserowaliśmy również między 9 – 16 września oraz w ostanim tygodniu miesiąca.
Zmiany znajdziesz na wykresach 1-3.
Przywykliśmy już do tego, że Google systematycznie informuje nas o wprowadzaniu globalnych zmian w algorytmie lub aktualizacjach skupiających się na konkretnym wycinku (weźmy, chociażby Page Experience Update). Czerwiec był, pod kątem informacji z tych gatunków, miesiącem zdecydowanie intensywnym. Poniżej podsumowanie najważniejszych czerwcowych newsów.
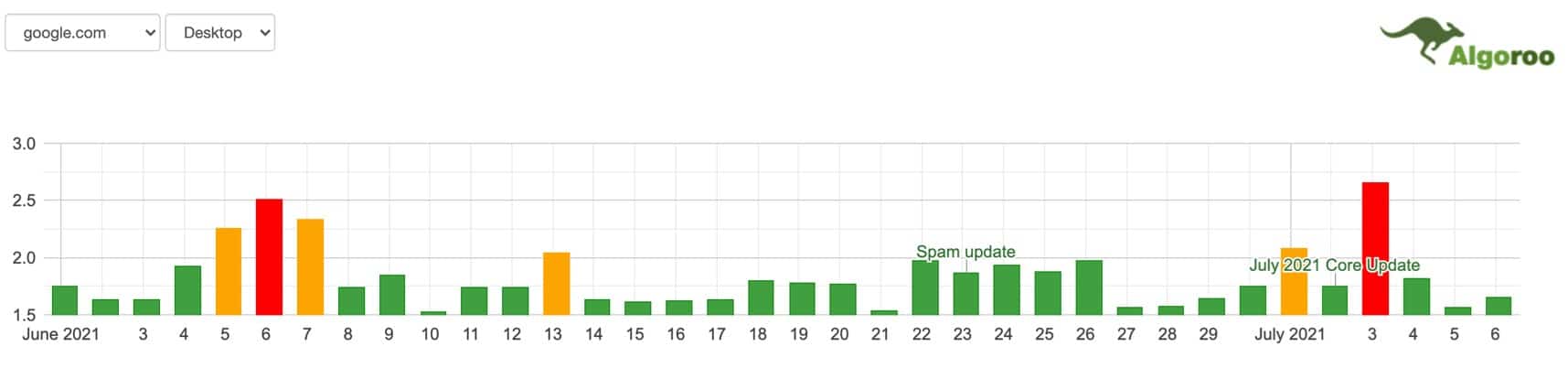
2 czerwca Google opublikowało informację o rozpoczęciu wprowadzenia kolejnego Core Update’u. Ostatecznie wdrażanie aktualizacji zakończyło się 12 czerwca. Update nazwany "June 2021 Core Update" to pierwsza potwierdzona globalna aktualizacja od grudnia 2020 roku. Od Google nie dowiedzieliśmy się jednak zbyt wiele na jej temat. Pewne wahania dla części stron były zauważalne. Również narzędzia do monitorowania zmian w wynikach wyszukiwania sygnalizowały, że „coś się dzieje”. Fluktuacje te nie były jednak aż tak intensywne jak w przypadku innych core’owych update’ów.
Zdecydowanie interesującym uzupełnieniem powyższej informacji jest natomiast fakt rozbicia, planowanych poprawek w algorytmie, na 2 aktualizacje. Przekazując informację o powyższym czerwcowym updacie, Google ogłosiło już kolejny Core Update, który ma mieć miejsce w lipcu. Dwie globalne aktualizacje, następujące po sobie miesiąc po miesiącu są sytuacją nietypową. Zdecydowanie warto więc odnotować ten fakt. Ponadto na dzień, w którym piszę ten wpis (tj. 05.07), obserwujemy już zauważalne fluktuacje w wynikach wyszukiwania, spowodowane z bardzo dużym prawdopodobieństwem właśnie lipcową aktualizacją. Jej wdrażanie rozpoczęło się już pierwszego dnia miesiąca. Więcej na ten temat na pewno napiszemy przy okazji kolejnego podsumowania.
W połowie czerwca Google potwierdziło rozpoczęcie wdrażania Google Page Experience Update, czyli aktualizacji związanej z metrykami Core Web Vitals. Zgodnie z informacjami ze strony Google wdrażanie aktualizacji będzie odbywało się dość powoli i ostatecznie jej wprowadzanie zostanie zakończone pod koniec sierpnia 2021.
Więcej na temat tej aktualizacji dowiesz się również z odcinka Core Web Vitals w pigułce naszego podcastu – Dziennik Budowy Firmy.
23 czerwca Google potwierdziło również inną aktualizacją algorytmu, tym razem skupioną na walce ze spamem. Update ten był rozbity na dwie części i druga z nich miała miejsce 28 czerwca. Ma on na celu filtrowanie wyników wyszukiwania, eliminując tym samym jeszcze większy procent spamu i szkodliwych stron. Wymierzony jest więc przede wszystkim w strony o niskiej jakości i wysokiej szkodliwości. Większych szczegółów omawianego update’u Google niestety nie przedstawiło.
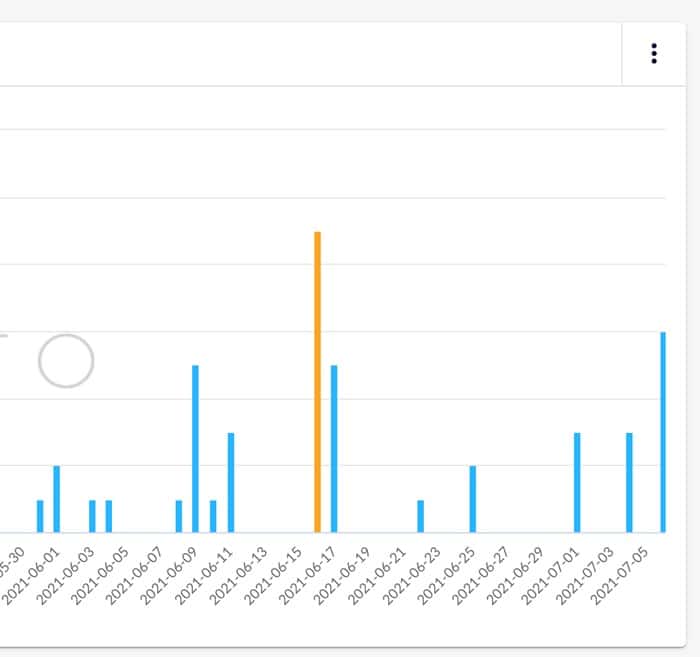
Pierwsza połowa czerwca była dość intensywnym okresem, jeżeli chodzi o fluktuacje w wynikach wyszukiwania. Mogliśmy zaobserwować całkiem sporo wahań wychodzących poza normę. Największe wahania narzędzia odnotowały pomiędzy 5- 17 czerwca, kiedy to faktycznie zmiany w algorytmie były wprowadzane.
ŹRÓDŁO 1: HTTPS://WWW.SEMRUSH.COM/SENSOR/ŹRÓDŁO 2: HTTPS://APP.SENUTO.COM/VISIBILITY-ANALYSIS/SERP-WEATHERŹRÓDŁO 3: HTTPS://ALGOROO.COM/
Po dużej aktualizacji algorytmu Google’a z początku grudnia, styczeń był spokojniejszym okresem, pod względem większych poprawek w algorytmie i potencjalnych przetasowań w wynikach wyszukiwania. Niemniej jednak kilka mniejszych aktualizacji mogło zostać wprowadzonych, na co wskazują statystyki, które znajdziesz na końcu tego wpisu.
Styczeń na pewno nie był jednak nudnym miesiącem, ponieważ kilka istotnych zmian i newsów ze strony Google, mogliśmy usłyszeć. Poniżej podsumuję najważniejsze z nich ☺
W pierwszej połowie stycznia dowiedzieliśmy się, że w listopadzie 2020 weszła w życie pewna poprawka w algorytmie Google. Dotyczyła ona tzw. podtematów (subtopics) i wpłynęła na około 7% zapytań. Aktualizacja ta związana jest z uczeniem maszynowym oraz mechanizmami AI, na które Google stawia obecnie bardzo mocny nacisk. Poprawka ta ma pomóc Google’owi wyświetlać maksymalnie zróżnicowane wyniki wyszukiwania, tak żeby zwiększyć szansę, że będą one spójne z intencją naszego zapytania. Przykładowo wyszukując hasło „sprzęt do ćwiczeń w domu”, Google dopasuje do takiego zapytania podtematy: sprzęt budżetowy, sprzęt premium, sprzęt do ćwiczeń w małym pomieszczeniu.
Z końcem stycznia Google przestało wspierać schemat danych strukturalnych data-vocabulary.org. Zmiana ta była zapowiedziana od ponad roku, nie powinna więc być zaskoczeniem. Obowiązującym standardem jest teraz schema.org. Jeżeli korzystasz więc jeszcze ze schematu data-vocabulary.org jest to najwyższa pora na zmianę.
Google Chrome od wersji 88 pozwala, w trybie developerskim, na analizowanie i testowanie wskaźników Core Web Vitals (Podstawowe Wskaźniki Internetowe).Przypominam, że Google zapowiedziało, że od maja 2021 Core Web Vitals będą czynnikami rankingowymi. Jeżeli zastanawiasz się więc czy teraz jest właściwy moment na zgłębienie się w temat i wprowadzenie poprawek na stronie pod ich kątem, odpowiedź brzmi: zdecydowanie tak.
Również w Google Search Console w styczniu pojawiło się kilka zmian. Wprowadzony został m.in. nowy raport dla wydawców w Google News (nie myl z filtrem „News”, jest to osobny raport dostępny tylko dla stron pojawiających się w Google News). Natomiast dotychczasowy raport dotyczący crawlowania został rozbudowany o nowe informacje dotyczące statusów oraz błędów.v
I na koniec: Google grozi wycofaniem się z Australii, jeżeli tamtejszy rząd nie zrezygnuje z wprowadzania nowego prawa, nakazującego zapłatę za wyświetlanie newsów z australijskich serwisów prasowych. Sprawa cały czas w toku, zdecydowanie warto śledzić.
Styczeń był spokojnym okresem, jeżeli chodzi o fluktuacje w wynikach wyszukiwania. Mogliśmy zaobserwować kilka wahań wychodzących poza normę, jednak nie zauważyliśmy ich większego odbicia na większości stron.Największe wahania narzędzia odnotowały między 7, a 12 stycznia, kiedy to faktycznie pewne zmiany w algorytmie mogły zostać wprowadzone.
Na początku czerwca odnotowaliśmy problem z indeksacją nowych treści, który został potwierdzony przez Google. Błąd ten był najbardziej problematyczny dla dzienników internetowych oraz innych portali opierających się na „świeżości” treści. Podobne problemy związane z indeksacją nowych treści zdarzały się już wcześniej w tym roku, jak i w latach ubiegłych. Na szczęście w tym przypadku błąd został rozwiązany w ciągu około 2 dni od jego wykrycia.
W czerwcu został naprawiony przez Google jeszcze jeden błąd związany z indeksowaniem. Chodzi o moduł komentarzy Disqus, pojawiający się często na blogach internetowych. Moduł ten opiera się w głównej mierze na JavaScript i mimo tego, że od dłuższego czasu Google radzi sobie już całkiem dobrze z renderowniem kodu JS i indeksowaniem treści na nim opartych, tak nie wszystkie komentarze z Disqus’a były do tej pory indeksowane. 20 czerwca Martin Splitt z Google poinformował, że problem został rozwiązany dla wszystkich stron.
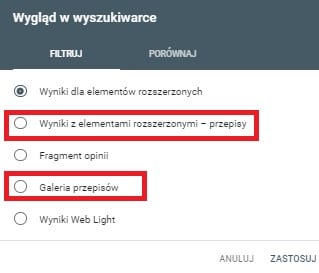
Na początku czerwca pojawiły się również w Google Search Console nowe udoskonalenia. Obejmują one nowe typy filtrów, możliwe do wykorzystania w raporcie Skuteczności. Dotyczą one tzw. rich snippet’ów (fragmentów rozszerzonych) dla przepisów kulinarnych. Od tej pory możecie wyizolować w raporcie statystki odnoszące się tylko do wspomnianych snippet’ów i oceniać ich efektywność.
Źródło: Google search console
Jest to już kolejne w ostatnim czasie udoskonalenie w GSC związane z obsługą danych strukturalnych. Możemy na tej podstawie wnioskować, że będzie to coraz ważniejszy element optymalizacji wyników wyszukiwania i warto na bieżąco śledzić wszystkie nowinki z nimi związane i dbać o poprawność wdrożenia.
Początek czerwca był stosunkowo spokojnym okresem, jeżeli chodzi o fluktuacje w wynikach wyszukiwania. Mogliśmy zaobserwować kilka wahań wychodzących poza normę, jednak nie zauważyliśmy ich większego odbicia na większości stron. Końcówka czerwca obfitowała natomiast już w zdecydowanie bardziej zauważalne wahania, co może sugerować, że pewne większe zmiany w algorytmie zostały wprowadzone.Do tej pory nie zostały jednak potwierdzone przez Google. Dodatkowo w polskich wynikach wyszukiwania nie zaobserwowaliśmy tak dużych wahań, jak w przypadku anglojęzycznych zapytań. Są głosy mówiące, że wspomniana aktualizacja może być poprawką aktualizacji algorytmu z maja, o której pisaliśmy w podsumowaniu poprzedniego miesiąca, które możecie sobie przypomnieć tutaj. Na chwilę obecną nie jesteśmy jednak w stanie w 100% potwierdzić tej informacji. Poniżej prezentujemy wykresy zmian w wynikach wyszukiwania z narzędzi do monitorowania SERPów.
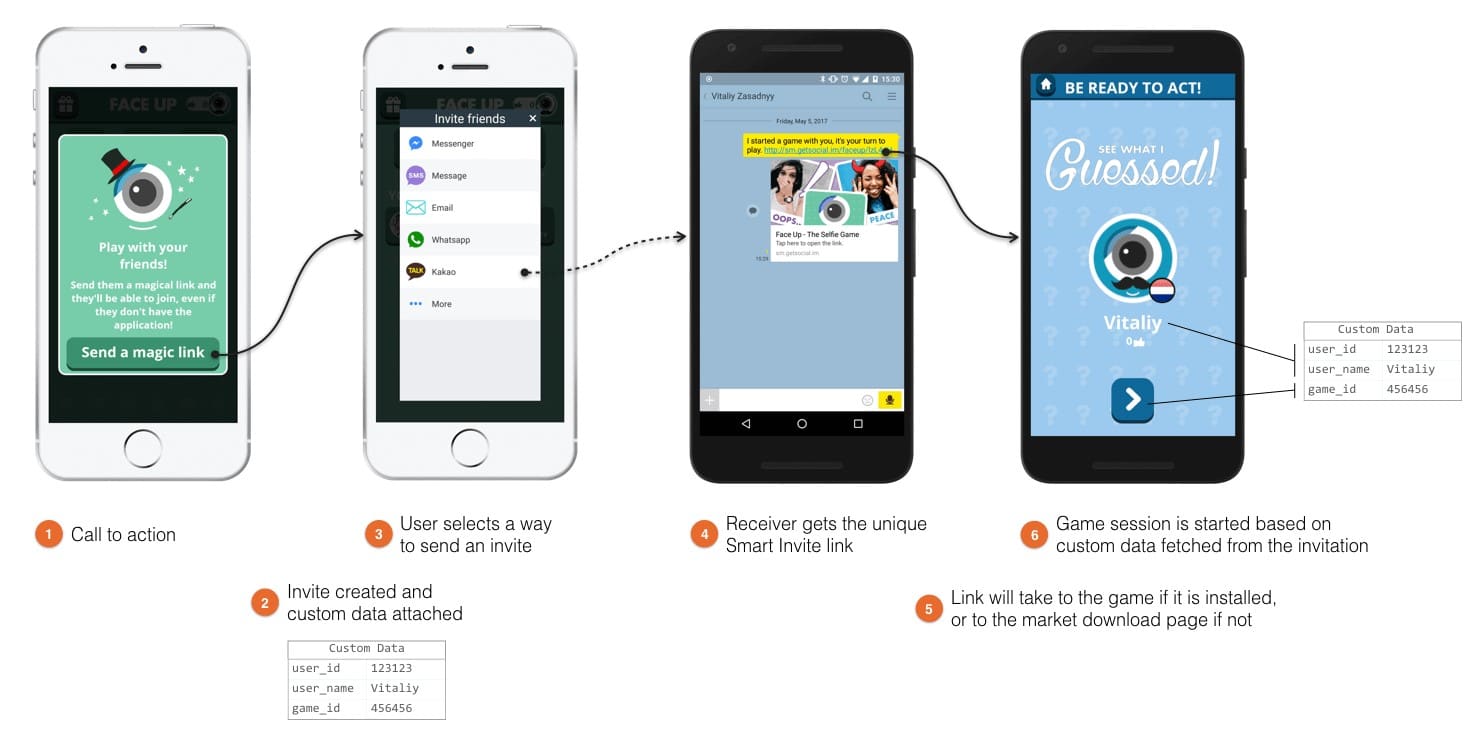
Sama koncepcja deep linków (dosłownie: głębokich linków) powinna być doskonale znane osobom zajmującym się szeroko pojętym marketingiem internetowym. Niekoniecznie będzie jednak zaszufladkowana w głowie akurat pod tym pojęciem. Celem przypomnienia – deep link to po prostu link do wewnętrznego elementu np. strony internetowej, czy aplikacji mobilnej. Deep linkiem będzie więc na przykład: https://foxstrategy.pl/pozycjonowanie-aplikacji/, ale nie będzie to https://foxstrategy.pl/. Dzisiaj nie będziemy się jednak skupiać na linkach w obrębie stron internetowych. Zagłębimy się natomiast w to jak operować specyficznymi typami deep linków, wykorzystywanymi w przypadku aplikacji mobilnych. Wprowadzę Was w zagadnie tego jak za pomocą deep linków możemy połączyć naszą aplikację mobilną ze stroną internetową i móc przekierowywać użytkownika do konkretnych „podstron” aplikacji. Zagłębimy się również w rodzaje deep linków, zasady ich funkcjonowania, korzyści z ich wykorzystania oraz szerokie możliwości użycia w rozmaitych kampaniach marketingowych. W niniejszym artykule nie będę się skupiał natomiast na dokładnych metodach implementacji deep link’ów (to temat na osobny wpis 😉), a na ogólnej koncepcji, metodach ich wykorzystania i korzyściach jakie mogą przynieść.
Rodzaje deep linków
Standardowe linki, takie jakimi posługujemy się na co dzień, zarówno w linkowaniu wewnętrznym na stronach, jak i odnośnikach zewnętrznych prowadzących do naszej strony www, w przypadku kliknięcia na urządzeniu mobilnym, przeniosą nas na naszą stronę internetową. Co wydaje się całkiem logiczne, biorąc pod uwagę ich funkcję. Co jednak w przypadku gdy mamy aplikację mobilną, do której chcemy sprowadzać użytkowników i która lepiej odpowiada ich potrzebom? W tym momencie wkraczają właśnie tzw. mobile deep linki, za pomocą których możemy rozwiązać ten problem. Deep linki umożliwiają przekierowywanie użytkownika do konkretnej zawartości w aplikacji mobilnej, nie tylko „strony głównej” aplikacji.
Żeby rozjaśnić trochę bardziej jak to w zasadzie funkcjonuje rozważmy kilka hipotetycznych sytuacji:
Przypuśćmy, że posiadasz aplikacje do streamowania muzyki (np. coś w stylu Spotify). W newsletterze mailowym chcesz podsyłać użytkownikom listy nowych albumów, tak żeby możliwe było bezpośrednie przejście do danego albumu i odtworzenie go bezpośrednio w aplikacji.
Drugi przypadek – posiadasz aplikację mobilną dla swojego sklepu z butami. W celu zaangażowania użytkowników w jej korzystanie oferujesz 10% zniżki dla zamówień zrealizowanych za pomocą aplikacji. Tworzysz w obrębie strony landing page z informacją o zniżce i linkujesz propozycje produktów, które użytkownicy mogą kupić za pośrednictwem aplikacji.
Ta sama aplikacja co w punkcie 2. Użytkownik kupił parę butów, które tak się mu spodobały, że chce udostępnić link do produktu innej osobie.
Użytkownik posiada zainstalowaną aplikację i chcesz przygotować spersonalizowanepowiadomienie push w telefonie, z informacją o zniżce na daną grupę produktów.
Aplikacja do zamawiania jedzenia z dostawą do domu – w danej okolicy otwiera się nowa restauracja, chcesz wysłać użytkownikom zamawiającym z danej lokalizacji informacje o tym wraz z linkiem bezpośrednio do menu nowej restauracji.
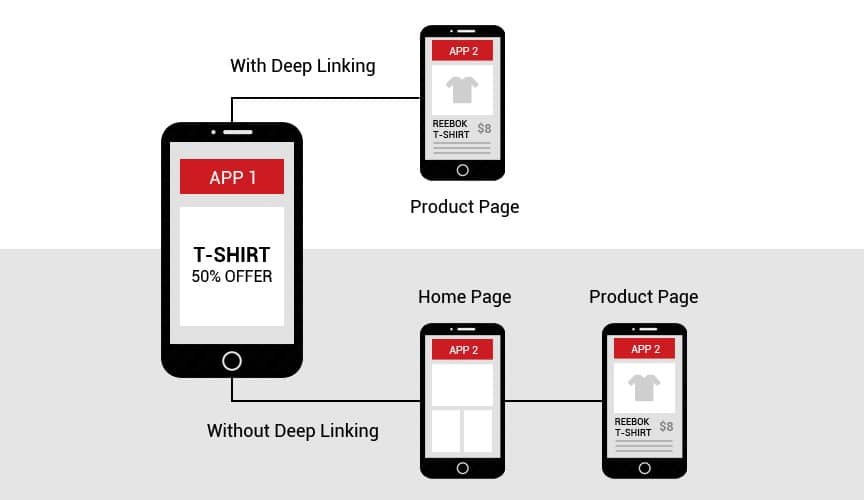
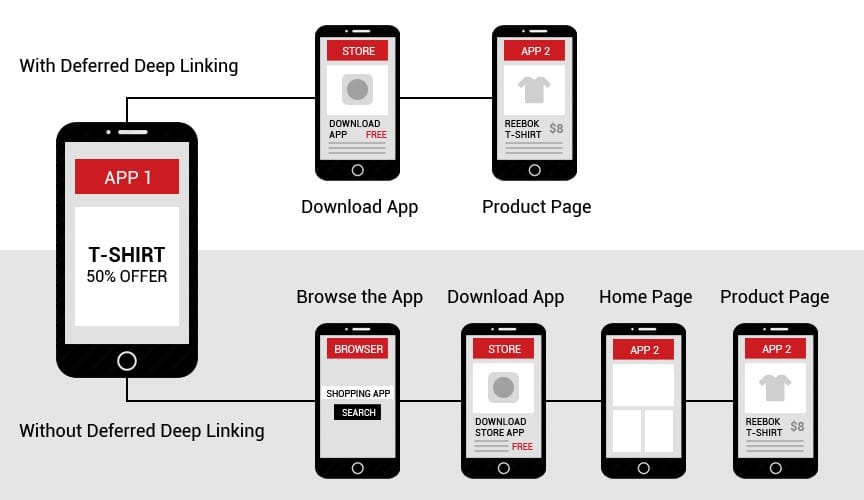
Przykłady takie możemy mnożyć w nieskończoność. Wszystkie je łączy jednak to, że w przypadku braku prawidłowo wdrożonych deep linków, użytkownik otrzymujący odnośnik do danego produktu, kategorii, czy ogólnie rzecz ujmując ekranu aplikacji, zostanie przekierowany na główny, startowy ekran. I to w sytuacji, gdy ma już zainstalowaną naszą aplikacje na telefonie. W przeciwnym razie napotkamy kolejny problem, ale o tym za chwilę. Opisaną sytuację bardzo dobrze obrazuje poniższa grafika.
Deep linki są więc konieczne, aby przekierować użytkownika od razu „w głąb” aplikacji, do miejsca docelowego.
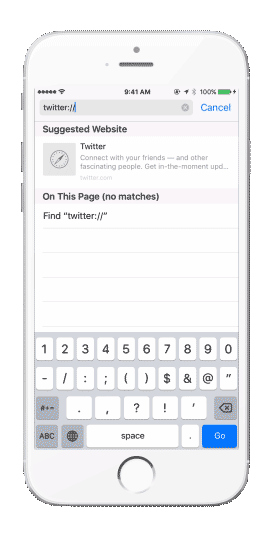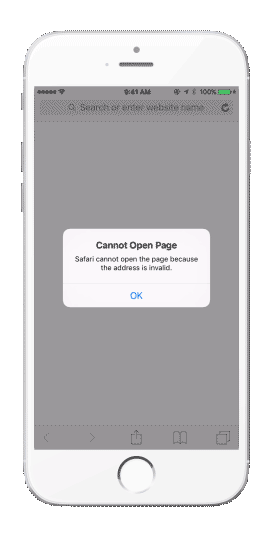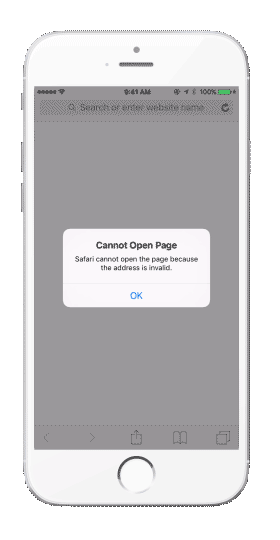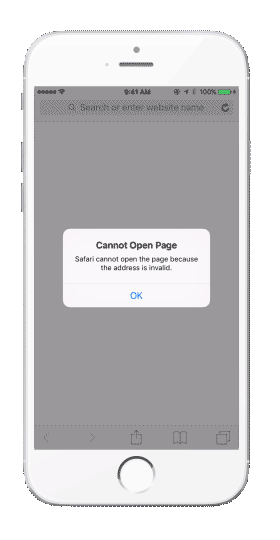
Patrząc na powyższe możemy uznać, że będzie to rozwiązanie wszystkich problemów, użytkownik zostanie zawsze przekierowywany do właściwego ekranu w aplikacji, jego zaangażowanie utrzymane, a my osiągniemy swój cel sprzedażowy. Niestety tak nie jest. Kolejną przeszkodą jaką napotkamy będzie sytuacja, w której użytkownik nie posiada zainstalowanej naszej aplikacji, a otrzyma link do jej zawartości. W tym przypadku napotkamy sytuację jak na poniższym gifie:
W sytuacji, gdy będziemy chcieli otworzyć link do appki, a nie posiadamy jej zainstalowanej, pojawi się komunikat o błędzie i ścieżka podróży konsumenta przez aplikację zostanie boleśnie przerwana.
Wtedy z pomocą przychodzą nam tzw. deferred deep links.
Deferred Deep Links
Mimo pozornie przerażającej nazwy sama koncepcja deffered deep linków (w dosłownym tłumaczeniu: odroczone/opóźnione linkowanie głębokie, jak ktoś ma lepszy pomysł na tłumaczenie, dawajcie znać w komentarzach :D) nie jest niczym skomplikowanym. Deffered deep linki pozwalają nam poradzić sobie z sytuacją, gdy użytkownik nie posiada zainstalowanej naszej aplikacji. Jeżeli prawidłowo wdrożyliśmy deffered deep linki, zostanie on przekierowany najpierw do sklepu (Google Play lub App Store, w zależności od systemu operacyjnego), a następnie, po zainstalowaniu aplikacji i jej uruchomieniu, do docelowego ekranu aplikacji.
Jak wynika z samego pojęcia (deferred, czyli odroczony, wstrzymany) przejście po linku jest odłożone w czasie do momentu zainstalowania aplikacji. W praktyce wygląda to jak na poniższym przykładzie.
Żeby było jeszcze weselej wprowadzimy jeszcze jeden typ deep linków, o wdzięcznie brzmiącej nazwie contextual deep links.
Ten typ linków posiada wszystkie funkcjonalności deffered deep links oraz dodatkowo możliwość przechowywania i śledzenia zachowań i interakcji użytkownika np. skąd do nas trafił, kto udostępnił link, z jakiej kampanii marketingowej przyszedł. Dzięki temu rozwiązaniu możemy np. przekierować użytkownika do zindywidualizowanego ekranu powitalnego albo umożliwić automatyczne zastosowanie kodu rabatowego.
Contextual deep links pozwalają więc na mocną personalizację zawartości aplikacji pod użytkownika lub ich grupę oraz ułatwiają analizy skuteczności danych kampanii.
Użytkownik otrzymujący link do konkretnej zawartości aplikacji jest przekierowywany bezpośrednio do niej. Nie musi rozpoczynać wędrówki od ekranu startowego, ląduje od razu w punkcie docelowym.
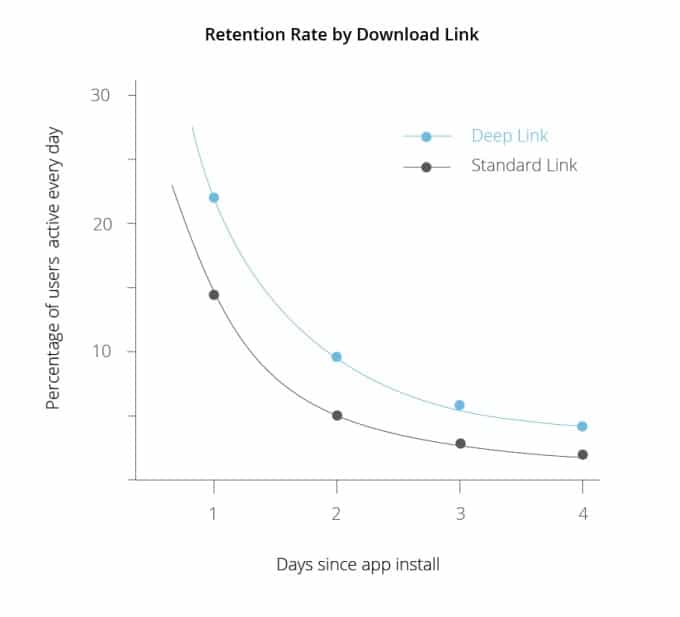
Zwiększają retencję w aplikacji
Retencja, czyli aktywne korzystanie z aplikacji w określonym czasie. Korzystanie z aplikacji mobilnych często niestety sprowadza się do pobrania, uruchomienia jednokrotnie i zapomnienia o jej istnieniu.
Zgodnie z badaniami przeprowadzonymi przez TechCruch contextual deep linki mogą poprawić retencję, w ciągu kilku pierwszych dni korzystania z aplikacji, o prawie połowę.
Dzięki contextual deep linkom możesz spersonalizować komunikację aplikacji pod danego użytkownika, dzięki czemu masz większą szansę przyciągnąć jego uwagę na dłużej.
Ułatwiają ponowne zaangażowanie użytkowników
Wiele aplikacji mobilnych cierpi na wspomniany wcześniej problem sprowadzający się do ich pobrania, wykorzystania raz i odejściu w niepamięć. Z pomocą mogą przyjść wszelkie kampanie promocyjne poza samą aplikacją np. za pomocą e-mail marketingu, kampanii Google Ads, czy innych kampanii marketingowych. Zaangażować użytkownika mogą nam również pomóc powiadomienia push na samym urządzeniu mobilnym, w których możemy np. zaproponować kupon rabatowy lub pochwalić się nowymi funkcjonalnościami. Wszystkie te działania nie przyniosą jednak rezultatu (lub przyniosą w ograniczonym stopniu), jeżeli użytkownik trafi na główny ekran startowy aplikacji, a nie do konkretnej jej „podstrony”, na której promocji nam zależy. Rozwiązaniem w tym przypadku również będą deep linki. Np. powiadomienie push z aplikacji Netflix o tym, że przerwałeś oglądanie odcinka ulubionego serialu w połowie i propozycja powrotu do dalszego oglądania.
Poprawiają widoczność aplikacji w wyszukiwarce Google
Wyszukiwarka Google z powodzeniem jest w stanie indeksować linki pojawiające się w obrębie aplikacji. Jeżeli dodatkowo posiadasz aplikację bogatą w content, będzie w stanie wyświetlać się na powiązane frazy kluczowe w wynikach wyszukiwania.
Pozwalają lepiej analizować skuteczność prowadzonych kampanii
Jak już wcześniej wspominałem contextual deep linki są wstanie przechowywać dane na temat użytkowników i ich zachowań. Dzięki takim danym łatwo będziemy mogli ocenić skuteczność danych kampanii reklamowych. Sprawnie ocenisz również efektywność poszczególnych kanałów marketingowych.
Gdzie wykorzystywać deep linki?
Ok, mamy już korzyści wynikające z użycia deep link’ów, teraz została nam tylko kwestia, gdzie ich używać. Poniżej kilka przykładów ich wykorzystania 😉
Linkowanie aplikacja -> aplikacja
Deep linki umożliwiają przekierowanie użytkownika między jedną aplikacją a drugą, do konkretnej zawartości tej drugiej appki. Przykładowo prowadzimy kampanię marketingową aplikacji do rezerwacji hoteli. Używamy do tego celu płatnej kampanii na Fecebooku i promujemy konkretny hotel. Użytkownik korzystający z aplikacji Facebook’a trafia na reklamę i klika w odnośniki. Przy prawidłowo wdrożonych deep linkach, użytkownik zostanie przekierowany bezpośrednio do naszej aplikacji na „podstronę” danego hotelu. W sytuacji, gdy nie posiada zainstalowanej aplikacji, zostanie przekierowany najpierw do sklepu Google Play lub App Store, a następnie po jej zainstalowaniu, przeniesiony na „podstronę” hotelu z naszej kampanii promocyjnej.
Kampanie mailingowe
Coraz większa liczba użytkowników odbiera pocztę na telefonie. Za pomocą prawidłowo skonfigurowanych deep linków możesz przekierować użytkownika bezpośrednio z wiadomości mailowej do wybranego ekranu w Twojej aplikacji.
Kampanie SMS
Podobnie jak w pozostałych typach kampanii i w kampanii SMSowej możesz wykorzystać deep linki np. proponując restaurację oferującą jedzenie na wynos w pobliżu i przenieść użytkownika bezpośrednio do menu.
Linki polecające (referrale)
Z powodzeniem możesz wykorzystać referrale np. do udostępnienia wyniku w grze i zaproszenia znajomego do wspólnej zabawy. Ponadto dzięki contextual deep linkom możesz zbierać dane na temat tak udostępnionych odnośników oraz je personalizować np. przyznając kod rabatowy użytkownikom polecającym Twoją aplikację.
Banner na stronie internetowej
Last but not least, czyli najczęściej chyba wykorzystywana forma promocji aplikacji w formie bannera na stronie. Dzięki deep linkom możesz być pewny, że użytkownik trafi we właściwe miejsce w Twojej aplikacji, a przy użyciu contextual deep linków zmierzysz efektywność takiego rozwiązania.
To tylko niektóre przykłady wykorzystania deep linków. W zależności od strategii promocji aplikacji, może być ich o wiele więcej.
Deep linkowanie w aplikacjach mobilnych to bardzo złożony i na pierwszy rzut oka niełatwy temat. Mam nadzieję, że niniejszy artykuł rozjaśnił Wam o co w ogóle chodzi w samej koncepcji mobile deep linków i jakie korzyści mogą płynąć z ich rozbudowanego wykorzystania. Powyższe informacje to tak naprawdę zarys ogólnej koncepcji tego zagadnienia i wprowadzenie w temat. Celowo nie wnikałem w metody implementacji oraz różnice w ich wykorzystaniu w Google Play i App Store (niestety nie ma jednego ujednoliconego standardu, jesteśmy zmuszeni korzystać więc z różnego rodzaju rozwiązań). To jednak zostawimy sobie na kolejny raz 😉
Tym, którzy wytrwali do końca wielkie dzięki. Jeżeli macie jakieś własne doświadczenia lub przemyślenia odnośnie mobile deep linków, dawajcie znać w komentarzach. Jeżeli artykuł zainspirował kogoś z Was do zadbania o swoją aplikację mobilną i poprawienia jej kondycji w Google Play lub App Store, zapraszam serdecznie do zapoznania się z naszą propozycją współpracy w zakresie ASO, więcej na ten temat znajdziecie tutaj. Jeżeli chcielibyście natomiast samodzielnie poszerzyć i uporządkować swoją wiedzę w kontekście pozycjonowania aplikacji mobilnych, zapraszam do pobrania naszego e-booka: 7 najważniejszych aspektów ASO w Google Play.
Jeśli jesteś zainteresowany/a ścieżkami kariery w branży technologicznej i mobilnej, to świetnym źródłem ofert pracy może być portal Jooble. To platforma, która specjalizuje się w wyszukiwaniu ofert z różnych źródeł, umożliwiając użytkownikom znalezienie idealnej pracy dostosowanej do ich umiejętności i doświadczenia. Sprawdź dostępne oferty, wpisując w tej wyszukiwarce swoją lokalizację, np. Praca we Wrocławiu, i znajdź idealną okazję do rozwoju swojej kariery zawodowej.
1 marca w życie weszła zmiana w silniku wyszukiwarki Google, dotycząca atrybutu rel=”nofollow”, opisywana przez nas już szerzej w poprzednich raportach. Od tego dnia linki nofollow, są wykorzystywane jedynie jako wskazówka do indeksacji i crawlowania strony, nie bezpośrednia wytyczna. Na chwilę obecną nie zaobserwowaliśmy jednak większego wpływu wprowadzonej zmiany na obserwowane przez nas strony internetowe.
Na początku marca Google poinformował, za pośrednictwem bloga dla webmasterów, o fakcie przejścia 70% indeksowanych witryn na mobile-first indexing. Oznacza to, że zdecydowana większość indeksowanych stron internetowych jest już crawlowana za pomocą mobilnego Googlebot’a. Istotna w kontekście mobile-first indexing będzie spójność zawartości witryny na desktop i mobile oraz jej optymalizacja pod kątem urządzeń mobilnych. To natomiast czy strona przeszła już na mobile-first indexing można zweryfikować w Google Search Console, w raporcie Stan.
Pod koniec miesiąca w Google Search Console pojawiły się nowe udoskonalenia. Tym razem dotyczą one powiadomień mailowych oraz podsumowania statystyk strony z poziomu wyników wyszukiwania. Od tego momentu możemy zdecydować czy chcemy być powiadamiani o danych błędach lub ostrzeżeniach za pomocą wiadomości mailowej oraz to czy na stronie wyników wyszukiwania wyświetlać dane o witrynie, zaciągnięte z GSC.
Dane strukturalne odnoszące się do wydarzeń (Event Schema) zostały rozbudowane o możliwości nowych oznaczeń, do który zaliczymy odpowiednio: anulowanie wydarzenia, przeniesienie (na nieokreśloną przyszłość), przeniesienie (na określoną datę) oraz przekształcenie na wydarzenie online.
W porównaniu do lutego marzec był stosunkowo spokojnym miesiącem jeżeli chodzi o przetasowania w wynikach wyszukiwania. Pewną zwiększoną intensywność wahań zaobserwowaliśmy w pierwszej połowie miesiąca oraz pod koniec marca, w kilku ostatnich dniach. Poniżej prezentujemy wykresy zmian w wynikach wyszukiwania z narzędzi do monitorowania SERPów.
Koniec roku to niezmienny czas podsumowań. Z tej okazji postanowiłem zebrać najważniejsze, moim zdaniem, wydarzenia w branży SEO w minionym roku oraz w przystępny sposób podsumować je i uporządkować. Miesiąc po miesiącu przejdziemy przez zmiany jakie Google zaserwowało nam w 2019 roku, a jak zaraz doskonale się przekonacie było tego niemało. Zaczynamy więc!
Krótko podsumowując – 2019 na pewno nie był nudnym rokiem. Miały miejsce 3, potwierdzone przez Google, duże aktualizacje algorytmu, które odbiły się mocno na wielu stronach oraz aktualizację BERT, której skalę na ten moment jeszcze ciężko ocenić. W minionym roku bardzo dużo czasu poświęciliśmy pojęciom takim jak JavaScript SEO, YMYL, E-A-T, NLP, Structured Data. Myślę, że w najbliższym roku terminy te będą pojawiały się jeszcze częściej, w różnych kontekstach. Jest to po części naturalny efekt obecnych trendów w projektowaniu stron internetowych oraz aplikacji webowych, po części rozwoju samej wyszukiwarki Google. Rok 2019 był również okresem istotnych zmian w Google Search Console (a tak naprawdę zmianą całego narzędzia). Z drugiej strony obserwowaliśmy duże natężenie błędów w samym algorytmie wyszukiwarki, najczęściej związanych z problemami z indeksowaniem stron. Myślę, że to co działo się w minionym roku to zalążek tego nad czym Google będzie pracować w najbliższych latach. Jestem bardzo ciekawy co faktycznie przyniesie 2020 ale myślę, że podobnie jak w 2019 nie będziemy się nudzić.
Zapraszam również do lektury wpisu “Nowe atrybuty linków – opinie 17 ekspertów SEO”, z którego dowiecie się co o roku 2019 w branży SEO sądzi 17 ekspertów, których wypowiedzi zebraliśmy. Tymczasem, wraz z całym zespołem Fox Strategy, życzę Wam Wesołych Świąt, udanej zabawy sylwestrowej i do zobaczenia w 2020 roku 😊
Styczeń
Początek roku był stosunkowo spokojnym okresem, jeżeli chodzi o aktualizacje algorytmu i wahania w SERPach. Był to czas konsekwentnej migracji starej Search Console do jej nowej wersji oraz wprowadzania dodatkowych funkcjonalności. W styczniu John Mueller potwierdził, że przejście pozostałych 50% stron na mobile-first indexing będzie trudniejsze niż tych zmigrowanych do tej pory (informacja o przejściu pierwszych 50% stron na mobile-first indexing pojawiła się w grudniu 2018). Trudność ta wynika z większych różnic (pozostałych 50% stron) między wersją mobilną i desktopową.
W lutym dowiedzieliśmy się natomiast, że statystyki w Google Search Console dla stron z osobną wersją na urządzenia mobilne oraz wersją AMP będą konsolidowane do jednego, kanonicznego adresu URL. Google może zasugerować się naszym atrybutem rel=canonical ale nie musi – jest to jedynie wskazówka, której nie ma obowiązku wziąć pod uwagę. Również w przypadku ewentualnych duplikatów pojedynczych podstron lub tych gdzie atrybut rel=canonical kieruje pod inny adres, statystyki będą wskazywane dla wybranego, ujednoliconego, kanonicznego adresu URL. W przypadku wersji: pl i m.przykladowastrona.pl może się zdarzyć również tak, że część adresów kanonicznych będzie wybrana dla wersji desktop, a część dla mobile. Dalej będzie można filtrować statystyki np. po urządzeniu, bez utraty danych. - Pozostając przy zmianach w GSC – w lutym dodano do panelu możliwość analizy danych strukturalnych dedykowanych podstronom produktowym (znacznik Product) – szczególnie istotnych dla ecommerce’ów. Obecnie można już z pozycji GSC analizować potencjalne problemy z wdrożeniem mikroformatów, bez konieczności przechodzenia do narzędzia do analizy danych strukturalnych Google. - Pod koniec miesiąca na youtube’owym kanale Google Webmasters wystartował cykl nagrań poświęconych JavaScript SEO. Google w dalszej części 2019 będzie kładł coraz mocniejszy nacisk na tę technologię i edukację w temacie, warto więc śledzić nowinki na bieżąco.
Luty
Marzec
Rok rozpoczęliśmy spokojnie ale prawdziwe trzęsienie ziemi przyszło w marcu. Najważniejszym wydarzeniem był update głównego algorytmu, o nieoficjalnej nazwie „Florida 2”, nawiązującej do pierwszej dużej aktualizacji algorytmu wyszukiwarki z 2003 roku. Kilka faktów o „Florida 2”:Duży, globalny update, potwierdzony przez Google. Miał miejsce 12.03.2019. Można go po części uznać za korektę Medic Update’u z sierpnia 2018. Dla sporej części serwisów można było zaobserwować korelację – spadków/ wzrostów z Medic Update (zdarzały się strony, które w sierpniu mocno utraciły na widoczności, natomiast w marcu ją odzyskały – i na odwrót). Aktualizacja mocno dotknęła strony z obszaru YMYL. Spadki odnotowały nie tylko serwisy medyczne. Mocno oberwały serwisy z poważnymi błędami natury technicznej i niskiej jakości treściami. Jakby tego było mało w marcu John Mueller z Google potwierdził, że od dłuższego czasu komenda rel=”prev”, rel=”next” w mechanizmach paginacji nie jest przez Google’a obsługiwana. Informacja ta odbiła się szerokim echem w branży. Raczej ze względu na pozostawiający wiele do życzenia sposób zakomunikowania zmiany przez Google, niż jej realny wpływ. Bo i co miało się zmienić skoro znaczniki nie były już obsługiwane od dłuższego czasu. Pod koniec miesiąca finalnie wyłączono możliwość przeglądania raportów w starej wersji Google Search Console. Od tego czasu w poprzedniej wersji GSC możemy już tylko korzystać z narzędzi nieudostępnionych w jej nowej odsłonie.
Jeżeli popatrzymy na same zmiany w algorytmie w porównaniu do marca był to bardzo spokojny miesiąc. Nie był jednak tak spokojny jeżeli popatrzymy na listę problemów i błędów, z którymi borykał się Google. W pierwszej połowie miesiąca obserwowaliśmy anomalie w wynikach wyszukiwania spowodowane bugiem, przez który losowe strony były wyindeksowywane. Błąd ten pojawił się w dniu 05.04 i finalnie został rozwiązany 11.04. Bug został oficjalnie potwierdzony przez Google. 16 kwietnia Google poinformowało o kolejnym bugu związanym z indeksowaniem witryny w Google News. Dzień później problem został rozwiązany. Z kolei 26 kwietnia Google poinformował o błędzie, którego efektem był wybór nieprawidłowego adresu kanonicznego dla niektórych podstron. Bug ten mógł wpłynąć na błędne wyświetlanie breadcrumbs w wynikach wyszukiwania na urządzeniach mobilnych oraz w skrajnych przypadkach na problem z indeksacją części podstron. Natomiast pod koniec miesiąca dowiedzieliśmy się, że między 09.04 a 25.04 w narzędziu Google Search Console pojawiła się luka w zebranych danych (z wyłączeniem raportu skuteczności). Oznacza to, że dane takie jak np. stan indeksu były w tym okresie przedstawione błędnie.
Kwiecień
Maj
W maju odbyła się kolejna edycja konferencji Google I/O. Najważniejszą informacją konferencji, w kontekście SEO, było ogłoszenie przejścia Googlebot’a na silnik Evergreen Chromium. Oznacza to, że Googlebot od tej pory będzie obsługiwany przez aktualny silnik przeglądarki Chrome. Ponadto na blogu Google dla webmasterów pojawiła się informacja, że od 1 lipca 2019 wszystkie nowo utworzone strony będą indeksowane w myśl zasady „mobile-first indexing”. Tym samym jest to kolejny jasny komunikat dla webdeveloper’ów o konieczności budowania przyjaznych dla urządzeń mobilnych serwisów internetowych. Maj to również okres wprowadzenia kolejnych raportów dotyczących danych strukturalnych w GSC oraz obsługa nowych typów (FAQ i How-to) przez wyszukiwarkę. W drugiej połowie miesiąca uaktualniono Search Quality Raters Guidelines (poprzednia aktualizacja miała miejsce około rok wcześniej). Zmiany skupiły się mocno na „Page Quality” oraz E-A-T. Kolejny miesiąc z rzędu obserwowaliśmy problemy z indeksowaniem. Bug dotyczył indeksacji nowo dodanej treści na stronach www. Błąd ten spowodował wiele problemów indeksacji serwisów, które w ostatnim czasie dokonywały zmian na stronie.
Czerwiec upłynął pod znakiem kolejnej aktualizacji głównego algorytmu wyszukiwarki. Kilka kluczowych faktów na jej temat:Sytuacja o tyle nietypowa, że Google zapowiedziało update przed jego wprowadzeniem. Miał miejsce 03.06.2019. Kolejny raz aktualizacja dotknęła najmocniej stron z obszaru YMYL. Mogła być to kontynuacja bądź korekta update’u z marca 2019. Update nie oszczędził również bardzo dużych graczy. Brytyjski dziennik dailymail.co.uk udostępnił publicznie informacje o utracie ruchu na poziomie 50% w wyniku aktualizacji. Ponadto niezależnie od aktualizacji głównego algorytmu, w okresie 4 – 6 czerwca wdrożona została poprawka w algorytmie mającą na celu zwiększenie dywersyfikacji wyników wyszukiwania dla niektórych zapytań. Po jej wprowadzeniu w rankingu TOP10 miały nie pojawiać więcej niż 2 wyniki wyszukiwania dla tej samej domeny. W praktyce wyszło różnie i zmiany były raczej mało spektakularne.
Czerwiec
Lipiec
Lipiec był kolejny miesiącem, w którym obserwowaliśmy silne fluktuacje w wynikach wyszukiwania. Google nie potwierdziło jednak oficjalnie, że były w tym czasie wprowadzane istotne zmiany w algorytmie. Niemniej jednak sygnały płynące z narzędzi do monitorowania SERPów oraz obserwacja stron wskazywały, że zmiany, z dużym prawdopodobieństwem, mogły mieć miejsce. Wspomniana aktualizacja algorytmu została potocznie nazwana „Maverick”. Na blogu Google dla webmasterów została również udostępniona informacja o liczbie zmian w algorytmie, która w 2018 roku wyniosła 3200. Jakby tego było mało przeprowadzono również prawie 700 000 eksperymentów. Natomiast z końcem miesiąca Google poinformowało, że od 01.09.2019 nie będzie obsługiwał komendy noindex w pliku txt (nie mylić z meta tagiem noindex!). Rzadko używana komenda więc i sama zmiana przeszła bez większego echa.
Sierpień to kolejne problemy z indeksowaniem się nowych treści w wynikach wyszukiwania, bug został potwierdzony przez Google. Z kolei John Mueller (Google) po raz kolejny zwrócił uwagę na ocenę jakości stron z obszaru YMYL (Your Money or Your Life czyli serwisów mających wpływ na życie, zdrowie, szczęście, stabilność finansową). Z wypowiedzi możemy dowiedzieć się, że Google stara się dogłębnie analizować autorytet autora, osób oceniających daną treść oraz ogólną jakość domeny. W Google Search Console zostały natomiast dodane raporty dla kolejnych typów danych strukturalnych: Produkty, Sitelinks Searchbox oraz Uporządkowane dane niepodlegające analizie. To ostatnie odnosi się do danych strukturalnych, które nie mogły zostać przeanalizowane z powodu krytycznego błędu w składni, w wyniku którego Google nie będzie w stanie określić ich typu.
Sierpień
Wrzesień
Wrzesień to kolejny update algorytmu, zapowiedziany wcześniej przez Google. Nie był on tak spektakularny jak ten marcowy lub czerwcowy. Niemniej jednak duże przetasowania w wynikach były widoczne. Google oprócz informacji o aktualizacji nie udostępniło zbyt wielu danych na jego temat. W pierwszym miesiącu jesieni wprowadzona również została aktualizacja algorytmu odpowiadającego za elementy rozszerzone, a dokładniej snippet’y z oceną w postaci gwiazdek, pojawiające się w wynikach wyszukiwania. Aktualizacja została potocznie nazwana „Starmageddon” ze względu na spore wyczyszczenie SERPów z rzeczonych snippet’ów. We wrześniu miała miejsce jeszcze jedna duża zmiana. Tym razem związana z linkami. Polegała ona na wprowadzeniu nowych atrybutów linków: rel=”sponsored” oraz rel=”ugc”. Ponadto atrybut „nofollow” ma być od tego czasu traktowany jako wskazówka dla algorytmu, nie dyrektywa. Może więc zostać równie dobrze zignorowany. Po większą dawkę wiedzy w temacie zapraszam do artykułu na naszym blogu, w którym swoimi opiniami podzieliło się 17 ekspertów z branży: https://foxstrategy.pl/blog/nowe-atrybuty-opinie/ Wrzesień to również kolejna aktualizacja Search Quality Raters Guidelines, już druga w tym roku. Ponownie zmiany skupiały się mocno na stronach z obszary YMYL oraz ocenie ich jakości.
Zaczniemy od końca miesiąca, ponieważ wtedy miało miejsce najważniejsze wydarzenie, czyli informacja o aktualizacji BERT na rynku US. Według Google jest to największy skok naprzód w okresie ostatnich 5 lat. Aktualizacja ma na celu lepsze rozumienie intencji użytkownika wpisującego zapytanie. Jest powiązana z uczeniem maszynowym oraz NLP (natural language processing). Wciąż trudno ocenić jej skalę, faktycznie może być to jednak duży krok naprzód i zakładam, że dopiero początek większych zmian. W październiku wprowadzono również kolejne funkcje w GSC, czyli raport skuteczności oraz ulepszeń wideo. Był to kolejny miesiąc dyskusji o E-A-T. 10 października Gary Illyes z Google poinformował, że nie istnieje konkretny algorytm dedykowany E-A-T, jest to bardziej wynikowa działania pozostałych algorytmów.
Październik
Listopad
W porównaniu z poprzednimi miesiącami listopad był stosunkowo spokojnym okresem. Na początku miesiąca Google oficjalnie udostępniło wtyczkę SiteKit do WordPress’a. Pozwala ona na wyświetlanie statystyk z Search Console, Analytics’a oraz Google Ads, bezpośrednio w dashboardzie WP. Listopad to kolejny miesiąc udoskonaleń GSC. Tym razem wprowadzony zostaje raport szybkości monitorowanej domeny. Ponadto kolejny raz Google borykało się z problemami z indeksowaniem. Tym razem oberwało się witrynom posiadającym atrybut max-image-preview, z wartością ustawioną na none.
Na początku miesiąca Google poinformowało o zakończeniu wdrażania aktualizacji algorytmu w lokalnych wynikach wyszukiwania. Aktualizacja ta jest powiązana z neural matching i ma pomóc Google’owi w lepszym rozumieniu kontekstu i intencji wyszukania dla wyników lokalnych. Zmiana została wdrożona globalnie, dla wszystkich języków. Jej wpływ do tej pory nie był jednak specjalnie spektakularny. Kolejną bardzo ważną informacją było wprowadzenie aktualizacji BERT na pozostałych nieanglojęzycznych rynkach. Finalnie BERT zawitał w 70 wersjach językowych, w tym w polskiej. Na razie nie zaobserwowałem większych przetasowań w polskich SERPach ale może być to zapowiedź większych zmian. Natomiast od 15.12, dla niektórych stron, mogliśmy obserwować skok liczby zaindeksowanych podstron, według raportu w GSC. Nie jest on spowodowany jednak żadnymi anomaliami w obrębie samej strony, a zmianami wprowadzonymi w narzędziu przez Google. Począwszy od tego czasu w raporcie Stan w indeksie ma być z większą precyzją wskazywana liczba zaindeksowanych podstron. Z tego też powodu część z tych, które wcześniej były oznaczone jako Strona wykryta – obecnie nie zindeksowana, przeszło do raportu Prawidłowe. Pytanie nasuwa się jednak jedno: Czy wcześniej w takim razie statystyki były błędne i czy teraz są prawidłowe czy po prostu mniej błędne 😉 Pod koniec miesiąca mogliśmy zaobserwować 10-dniowe opóźnienie zbieranych danych w raporcie Stan w indeksie w Google Search Console. Błąd został naprawiony 1 stycznia. Między 16.12 – 17.12 w Google Analytics pojawił się bug mogący powodować lukę w zbieranych danych. Jeżeli w tym okresie widzicie anomalie w danych w GA może być ona spowodowana wspomnianym błędem. Został on potwierdzony przez Google i do końca miesiąca nie został jeszcze w pełni naprawiony. Sieć obiegła również informacja o pracy przez Google nad nowymi wytycznymi w kwestii paginacji (przypominam, że kilka miesięcy wcześniej pojawiła się informacja o niewspieraniu atrybutów rel=”prev” rel=”next”). W grudniu mogliśmy również obserwować zwiększone przetasowania w wynikach wyszukiwania. Oficjalnie żadna poprawka w algorytmie, oprócz aktualizacji BERT, nie została jednak potwierdzona.
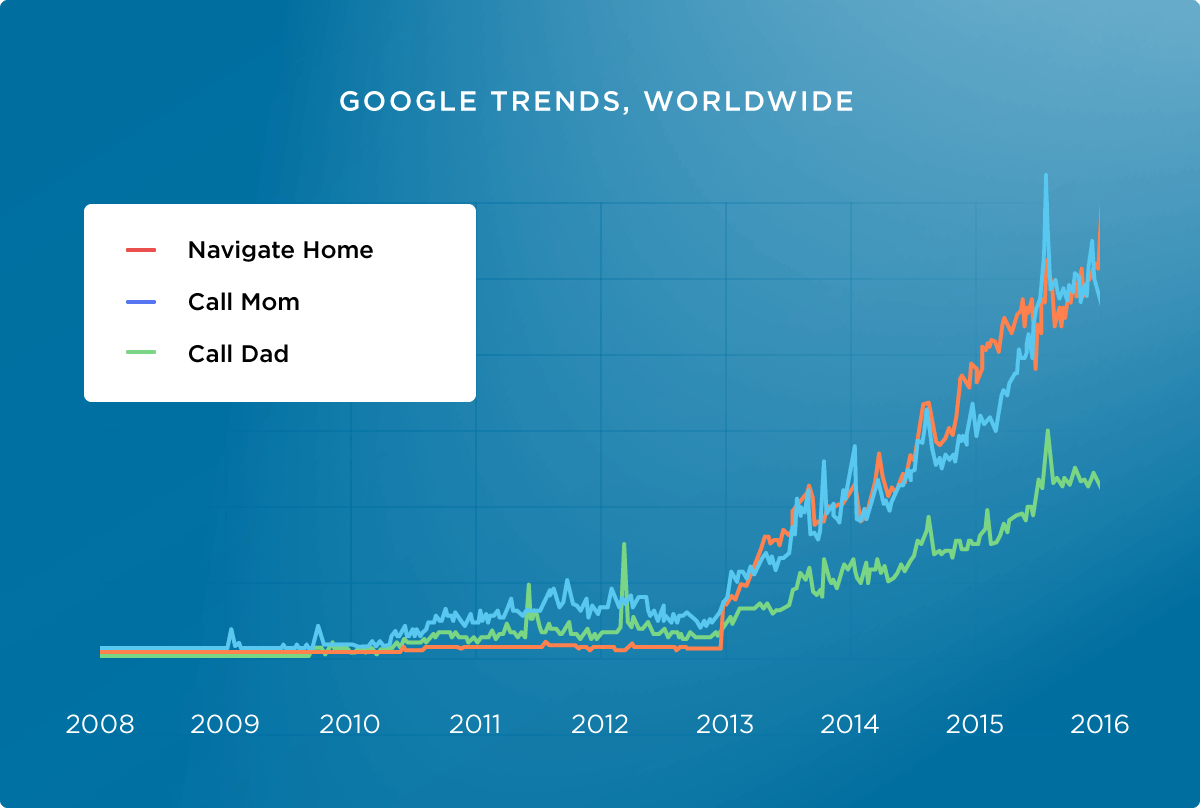
Technologia wyszukiwania głosowego wbrew pozorom nie jest nowością i w różnych formach funkcjonuje już od lat. W ostatnim czasie mówi się jednak o rewolucji jaką ta forma komunikacji z wyszukiwarką ma wprowadzić. Czy faktycznie tak jest? Czy nagle musimy przemodelować sposób przedstawiania informacji na stronach internetowych? Czy fakt, że wyszukiwanie głosowe zdobywa coraz większą popularność na rynkach anglojęzycznych jesteśmy w stanie przełożyć na polski rynek? Zapraszam do lektury faktów i mitów na temat wyszukiwania głosowego 😊
MIT: Wyszukiwanie głosowe to zupełnie nowa technologia
Pierwsza znana maszyna, rozpoznająca język mówiony, została zbudowana w 1952 roku w firmie Bell Labs. Nosiła nazwę Audrey i była w stanie zrozumieć jedynie cyfry. Pierwsze urządzenie będące w stanie rozpoznawać całe słowa zostało zaprezentowane, przez znaną wszystkim firmę IBM, dokładnie 10 lat później. Nosiło ono nazwę Shoebox i mogło rozpoznać zawrotną ilość 16 słów, w języku angielskim. Przeskoczmy jednak szybko o kilkadziesiąt lat do przodu, do roku 2007 czyli pierwszych prób zmierzenia się z wyszukiwaniem głosowym przez Google. Wówczas to na rynku amerykańskim pojawiła się usługa o nazwie GOOG-411. W skrócie polegała ona na połączeniu z darmowym numerem, wypowiedzeniu zapytania (nazwy firmy lub kategorii działalności np. restauracje). Następnie otrzymywaliśmy listę pasujących zapytań (maksymalnie 8) i system wykonywał połączenie telefonicznie do wybranego miejsca lub przysyłał wiadomość tekstową z numerem telefonu. Usługa obejmowała lokalne firmy i była udostępniona tylko w Stanach Zjednoczonych, funkcjonowała do roku 2010. Ważniejszą datą dla nas będzie jednak rok 2009, kiedy to Google wypuściło pierwszą mobilną aplikację obsługującą wyszukiwanie głosowe. Funkcja voice search pojawiła się w ramach Google Mobile App na iPhone’a.W 2012 roku została natomiast uruchomiona usługa Google Voice Search, która funkcjonuje do dzisiaj.
FAKT: Zapytania formułowane za pomocą głosu różnią się od tych pisanych
W zupełnie inny sposób formułujemy zapytania gdy wpisujemy je w wyszukiwarce, inaczej gdy robimy to za pomocą głosu. Zapytania głosowe będą dłuższe i bardziej precyzyjne, zwykle w formie pytań. Natomiast te wpisywane będą krótsze, hasłowe. Z tego też względu dobrze zoptymalizowana pod voice search strona powinna wyświetlać się na dużą ilość precyzyjnych fraz long tail, a treści w jej obrębie powinny odpowiadać na pytania użytkownika. Najlepiej w krótkiej i zwięzłej formie. W celu poznania o co ludzie pytają wyszukiwarkę możemy użyć narzędzi takich jak AnswerThePublic, zaciągających propozycje zapytań z modułu podpowiedzi Google’a.
MIT: Dostosowanie strony pod wyszukiwanie głosowe wymaga jej gruntownego przemodelowania
Jeśli poszukamy w sieci informacji o tym jak zoptymalizować stronę pod kątem wyszukiwania głosowego natrafimy na poradniki mówiące przede wszystkim o:
doborze słów kluczowych, skupiając się na frazach long-tail oraz bardzo precyzyjnych zapytaniach
tworzeniu treści precyzyjnie odpowiadających na pytania użytkowników
optymalizacji pod kątem featured snippet
dbaniu o przejrzystą i prostą strukturę treści
wdrożeniu danych strukturalnych
dbaniu o wersję mobilną strony i szybkość jej ładowania
Jak podsumujemy sobie wszystkie te elementy okaże się, że jeżeli zależy nam na o dobrej optymalizacji strony pod kątem SEO i „klasycznej” metody wyszukiwania, każdy z nich również powinien być wzięty pod uwagę. Sądzę więc, że nie ma potrzeby specjalnego „dostosowywania” strony pod voice search. Jeśli prowadzimy działania SEO zgodnie z obecnymi standardami powinniśmy już być gotowi na wyszukiwanie głosowe. Fakt ten wynika wprost z rozwoju mechanizmów wyszukiwania w kierunku wyszukiwania semantycznego oraz badaniu intencji użytkownika. Jeśli bardzo poważnie myślimy o voice search’u są oczywiście elementy, na które należy położyć silniejszy nacisk. Niemniej jednak, na dzień dzisiejszy, zazębiają się one bezpośrednio z optymalizacją również pod język pisany.
FAKT: Największą barierą w wyszukiwaniu głosowym jest ta psychologiczna
Zgodnie z badaniami przeprowadzonymi w 2016 roku przez firmę Creative Strategies[1], 39% użytkowników korzystających z wyszukiwania głosowego robi to w domu. Zwykle do tego celu używane są inteligentne głośniki, jak np. Google Home. 51% uczestników przebadanej grupy korzysta z wyszukiwania głosowego w aucie, 6% w przestrzeni publicznej, natomiast 1,3% w pracy. Z kolei 20% użytkowników, którzy nigdy nie korzystali z wyszukiwania głosowego, stwierdziło, że nie używają tej funkcji ponieważ nie czują się komfortowo rozmawiając z maszyną. Zwłaszcza przebywając w miejscach publicznych, w otoczeniu innych ludzi. Badania te liczą już co prawda ponad 3 lata i trochę od tego czasu mogło się zmienić. Zwróćmy jednak uwagę, że zostały one przeprowadzone w Stanach Zjednoczonych. Myślę, że w Polsce bariera ta może być jeszcze silniejsza, nawet na dzień dzisiejszy.
FAKT: Wyszukiwanie głosowe najlepiej (na chwilę obecną) sprawdza się w przypadku lokalnych biznesów
Zgodnie z raportem przygotowanym przez Score.org[2], 58% użytkowników korzystających z wyszukiwania głosowego w 2018 roku używało go do wyszukiwania informacji o lokalnych firmach. Najczęściej są to: restauracje, sklepy oraz hotele. Natomiast według statystyk opublikowanych przez Google w 2018 roku, na przestrzeni 2015 - 2017 liczba zapytań zawierających frazę „near me” wzrosła o ponad 150%. Często korzystamy w ten sposób z wyszukiwania głosowego np. jadąc autem i szukając konkretnego miejsca w pobliżu. Jeżeli prowadzicie biznes lokalny warto więc i ten fakt wziąć pod uwagę.
Myślę, żę w najbliższych latach voice search będzie pełnić coraz ważniejszą rolę. Jak widać na różnych statystykach wyszukiwanie głosowe zdobywa, z roku na rok, coraz większą popularność. Samo Google również z bardzo dużą intensywnością rozwija mechanizmy wyszukiwania głosowego. Wszystkie statystyki odnoszą się jednak do rynków anglojęzycznych, głównie do Stanów Zjednoczonych. Rynek ten w wielu aspektach różni się od naszego polskiego podwórka. Uważam, że większości raportów, badań czy statystyk nie możemy bezpośrednio przełożyć na polskojęzyczną wyszukiwarkę. Nie jest ona jeszcze tak zaawansowana jak jej anglojęzyczny odpowiednik (i zakładam, że nigdy nie będzie). Z roku na rok widzimy coraz większą postęp jeżeli chodzi o wyszukiwanie semantyczne, na początku roku wprowadzony został również na nasz rynek Asystent Google w rodzimym języku. Niemniej jednak nie możemy zapominać, że różnice w zaawansowaniu mechanizmów Google.pl i Google.com zawsze będą, zwłaszcza jeśli mówimy o wyszukiwaniu głosowym. Lepiej więc nie rzucać wszystkiego i skupiać całych sił na „optymalizacji pod voice search”. Dobra optymalizacja (z uwzględnieniem wciąż zmieniającego się algorytmu wyszukiwania) pod kątem „pisanych” zapytań będzie świetnym punktem wyjścia. Odnosząc się do twierdzenia z początku artykułu o rewolucji, która miałaby nadejść wraz z wyszukiwaniem głosowym, myślę, że powinniśmy myśleć o tym bardziej jako o ewolucji. Ewolucji sposobu w jaki algorytm Google’a przetwarza zawartość stron internetowych i dopasowuje wyniki do naszych zapytań.








 źródło:
źródło: