Indeksacja i wskazania kanoniczne
Optymalizacja SEO w odniesieniu do indeksacji ma na celu ustalenie zasad, które będą decydowały o tym, które strony mają pojawiać się w wynikach wyszukiwania Google. Krok drugi to przygotowanie „narzędzi”, które ułatwią Google dotarcie do poszczególnych adresów URL.
Wiele sklepowych platform niejako z automatu definiuje, które typy podstron są wyłączone z indeksacji, a które mogą być bez przeszkód analizowane przez roboty wyszukiwarki i rezultacie pojawiać się w wynikach wyszukiwania Google.
Zasady dotyczące dostępu do podstron i ich indeksowania można definiować w kilku miejscach:
- z poziomu serwera i pliku .htaccess - poprzez użycie konkretnych komend można zablokować dostęp zarówno do konkretnych podstron (czy zasobów) jak również całych sekcji (katalogów) działających w obrębie sklepu.
- z poziomu pliku robots.txt – zawarte w tym pliku komendy mogą określać blokadę dostępu zarówno w odniesieniu do określonych sekcji stronu jak i mając na uwadze konkretne roboty wyszukiwarek
- poprzez deklarację w metatagach i użycie komendy noindex
Zasady związane z dostępem dla robotów i indeksowaniem się stron można określać zarówno w odniesieniu do podstron, które dopiero zostały stworzone (i nie dotarły do nich jeszcze roboty wyszukiwarki) oraz będą pojawiały się w przyszłości (działania „prewencyjne”) jak również biorąc pod uwagę podstrony czy sekcje, które już od dawna funkcjonują w obrębie sklepu (czyli już w momencie, gdy adresy figurują w indeksie).
Dlaczego w ogóle blokuje się strony?
Najczęstsze powody to:
- chęć wykluczenia z wyników wyszukiwania niepożądanych podstron – mogą to być np. wszelkie sekcje, gdzie przechowywane są wrażliwe dane, pliki konfiguracyjne czy po prostu strony, które w naszej ocenie z jakiś względów nie powinny być widoczne z poziomu wyników wyszukiwania
- niedopuszczenie do indeksowania się (bezwartościowych / niepotrzebnych) podstron – czyli określenie z góry jakie adresy mają nie pojawiać się w wynikach wyszukiwania – może to dotyczyć np. stron wynikowych, generowanych na bazie wyszukiwarki wewnętrznej czy filtrowania, które nie mają żadnej wartości dodanej i z tego względu nie warto zezwalać Google na ich wyświetlanie w indeksie.
Przy okazji warto podkreślić, że zablokowanie robotom Google dostępu do podstron z poziomu pliku robots.txt nie oznacza, że strony te nie pojawią się w wynikach wyszukiwania Google (będą po prostu widoczne np. jako wylistowane adresy URL).
Aby mieć pewność, że dany adres nie pojawi się wynikach wyszukiwania zalecamy korzystanie z komendy „noindex”.
Zapis w kodzie strony:
<meta name="robots" content="noindex" />
Umożliwi robotom wejście i zapoznanie się z zawartością strony, ale uniemożliwi jej wyświetlanie się w wynikach wyszukiwania.
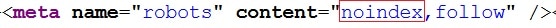
W przypadku sklepów internetowych warto sprawdzić, czy swobodny dostęp do ważnych podstron (na które będą trafiać potencjalni klienci), mają również roboty wyszukiwarki Google. W przeciwnym razie podstrony te, nie będą się wyświetlały w wynikach wyszukiwania, co znacznie zmniejsza szansę na pozyskanie ruchu w ich obrębie.
Narzędzia wspomagające indeksację
W odniesieniu do stron, które mają być indeksowane, warto wykorzystywać mechanizmy, które umożliwią Google nie tylko dotarcie do poszczególnych podstron, ale będą również określać ich priorytet bądź też informować o zmianach i konieczności ponownej indeksacji.
Głównym narzędziem jest mapa XML, czyli w pewnym uproszczeniu lista wszystkich ważnych adresów, do których Google powinno dotrzeć i które mają pojawiać się w wynikach wyszukiwania (na screen poniżej fragment mapy).

W przypadku dużych i rozbudowanych sklepów dobrą praktyką jest tworzenie osobnych map XML dla poszczególnych typów stron (czyli mapy dedykowanej dla kategorii i podkategorii, osobnej dla kart produktów i jeszcze innej np. dla artykułów czy grafik itp.) oraz jednej głównej (tzw. „mapy map”) zawierającej linki jedynie do stworzonych wcześniej map niższego rzędu.
Po wygenerowaniu map i ich opublikowaniu należy ułatwić Google dotarcie do nich poprzez umieszczenie adresu głównej mapy w pliku robots.txt oraz zgłoszenie poszczególnych map w Google Search Console (Indeksowanie --> Mapy witryn).
Wskazania kanoniczne (atrybut rel=”canonical”)
Wiele sklepów internetowych w swoich domyślnych ustawieniach posiada zaimplementowane w kodzie tzw. wskazania kanoniczne. Poprzez umieszczenie w sekcji head danej strony atrybutu rel=” canonical” (bo o nim mowa) można przekazać wyszukiwarce Google pewne wytyczne dotyczące rankingowania stron i ich zawartości. Canonicale pomagają ustalić np. to który adres spośród zbioru stron o bardzo zbliżonej (bądź nawet identycznej) zawartości ma być traktowany jako kluczowy. Dzięki temu można nadać priorytet jednej, „najważniejszej” podstronie i w pewien sposób ograniczyć wyświetlanie się w wynikach wyszukiwania pozostałych, mniej wartościowych podstron.
W przypadku optymalizacji czy wprowadzania nowych ustawień, w pierwszej kolejności należy wytypować stronę kanoniczną, czyli tę która ma być traktowana priorytetowo. Następnie na stronach (o identycznej lub bardzo podobnej zawartości, przed zamknięciem sekcji head) dodajemy komendę, która ma wskazywać na najważniejszy (czyli zdefiniowany wcześniej adres).
Dla przykładu, w kodzie strony https://projektwino.pl/wina/1/default/2 znajduje się następujący zapis:
<link rel="canonical" href="https://projektwino.pl/wina" />
Mechanizm dodawania canonicali najczęściej wykorzystywany jest:
- w przypadku stronicowania (paginacji) – wtedy najczęściej główny adres kategorii traktowany jest jako priorytetowy, a kolejne podstrony (czyli druga, trzecia, itd.) odwołują się do niego.
- dla stron generowanych na bazie zmiany widoku listy produktów – czyli wszędzie tam, gdzie możemy np. posortować produkty według określonego klucza (po cenie, nazwie produktu, dostępności itd.). Chodzi o to, że tak naprawdę dla każdego wygenerowanego w ten sposób nowego adresu prezentowane są te same dane (przez co nie mają one żadnej wartości dodanej i stanowią kopie) więc nie ma sensu, aby pojawiały się one w wynikach wyszukiwania.
- dla adresów generowanych po wyborze określonych filtrów z poziomu kategorii bądź podkategorii
- w odniesieniu do podstron prezentujących ten sam produkt i różniących się jedynie jedną cechą (np. rozmiarem, kolorem, gramaturą itp.). By częściowo rozwiązać problem powtarzających się opisów czy identycznej zawartości stron warto wskazać Google jedną kluczową podstronę poprzez umieszczenie na pozostałych wskazania kanonicznego na wybrany, najważniejszy adres
Zalecenia związane z indeksacją i wskazaniami kanonicznymi dla projektwino.pl
A) Strony wynikowe filtrowania po danym parametrze
Obecnie w zasadzie wszystkie podstrony generowane po wybraniu danego filtra z poziomu kategorii typu:
https://projektwino.pl/pl/c/Wino/59/1/default/1/f_at_188_0/1
https://projektwino.pl/wina/1/default/1/f_at_170_14/1
posiadają w kodzie wskazanie kanoniczne (atrybut rel=”canonical”).
Oznacza to, że strony te nie mają szans na to by pojawić się w wynikach wyszukiwania, ponieważ roboty Google otrzymują informację, by inną stronę (adres głównej kategorii) traktować jako priorytetowy i nadrzędny.
Tym samym sklep nie ma szans na wyświetlenie się w top10 wyników wyszukiwania dla zapytań powiązanych np. z kolorem wina, jego dopasowaniem do dania lub okazji czy typem itd.
By to zmienić zalecamy usunięcie canonicali ze stron generowanych po wybraniu filtrów takich jak:
- kolor (typu https://projektwino.pl/wina/1/default/1/f_at_168_2/1)
- typ (np. https://projektwino.pl/wina/1/default/1/f_at_170_13/1)
- styl (przykład: https://projektwino.pl/wina/1/default/1/f_at_171_33/1)
- okazja (jak np. https://projektwino.pl/pl/c/Wino/59/1/default/1/f_at_191_0/1)
- potrawa (https://projektwino.pl/pl/c/Wino/59/1/default/1/f_at_185_0/1) itd.
*Usunięcie canonicali powinno dotyczyć tylko podstron generowanych z poziomu głównej kategorii, czyli Wina (https://projektwino.pl/wina)
**Każda ze stron, które mają pojawić się w wynikach wyszukiwania, powinna posiadać unikalne wypełnienie meta tagów, tematyczny opis itd. Dodatkowo warto zoptymalizować adresu URL w taki sposób aby miały bardziej "przyjazną strukturę" (napiszemy o tym więcej w kolejnej części audytu).
Jeśli w przyszłości okaże się, że klienci szukają oferty dostępnej w sklepie po wybraniu więcej niż jednego filtra (np. wino białe wytrawne), również można będzie rozważyć usunięcie canonicali z takiego typu zawężania wyników, jednak w pierwszej kolejności strony te muszą być odpowiednio zoptymalizowane pod kątem SEO.
B) Podwójne canonicale
Obecnie na części podstron typu https://projektwino.pl/pl/c/Wino/59/1/default/1/f_at_188_0/1
Znajduje się wskazanie kanoniczne na adres https://projektwino.pl/pl/c/Wino/59
na którym następuje kolejne wskazanie na https://projektwino.pl/wina
Nie zalecamy tworzenia tego typu pętli i wielokrotnych wskazań (proponujemy, aby canonical odnosił się do jednego, głównego względem tej grupy podstron adresu, czyli https://projektwino.pl/wina ).
C) Plik robots.txt
Zalecamy usunięcie w pliku robots.txt dwóch pierwszy linijek, czyli komendy:
User-agent: *Crawl-delay: 30
oraz dodanie adresów wygenerowanych map XML.
Komenda może wyglądać np. tak:
Sitemap: https://projektwino.pl/console/integration/execute/name/GoogleSitemap
Dodatkowo komendy dotyczące blokowania poszczególnych adresów wymagają uaktualnienia, ponieważ na ten moment wskazanie na katalog jest nieaktualne, dla przykładu adres koszyka to https://projektwino.pl/pl/basket
Tymczasem blokada wskazuje na adresy w obrębie katalogu, czyli /basket/ itp.
D) Dodatkowe adresy do wyłączenia z indeksacji
Zalecamy wyłączyć z indeksacji dodatkowe strony, które nie powinny pojawiać się w indeksie. Można to zrobić poprzez umieszczenie dodatkowych komend w pliku robots.txt o którym pisaliśmy wyżej lub poprzez dodanie w kodzie strony komendy:
<meta name="robots" content="noindex, follow" />
Chodzi o adresy takie jak:
https://projektwino.pl/pl/i/Regulamin/2
https://projektwino.pl/pl/i/Polityka-prywatnosci/3
https://projektwino.pl/pl/basket
https://projektwino.pl/pl/login
https://projektwino.pl/pl/reg
https://projektwino.pl/panel/favourites
https://projektwino.pl/panel
https://projektwino.pl/panel/edit
https://projektwino.pl/pl/s
E) Mapa XML
Obecna mapa XML i „podmapy” (https://projektwino.pl/console/integration/execute/name/GoogleSitemap) są prawidłowe, jednak nie są zgłoszone w Google Search Console. Zalecamy ich poszerzenie o adresy które będą włączone do indeksacji oraz każdorazową aktualizację w przypadku pojawienia się np. nowych kart produktów, podkategorii czy podstron.
Latest posts by katarzyna
(see all)





